




An overview of 3D different methodologies and typical applications
3D techniques are used in various fields, from quality control to robot guide. Regarding the robot guide it is necessary not to confuse the vision system computing time necessity with the needs of the robot (also as the calculation takes time is typically made in advance on the movements of the robot).
A general advantage of the 3D is the substantial independence from color, although the details will vary depending on the technique.
The necessity of having a moving object or a stationary one can be both an advantage and a disadvantage (eg. It is an advantage to have it in motion if it is already on a conveyor belt). The techniques that require a single image (snap) are independent from the movement of the object.
In this field of action the techniques we use are referring of two main branches:
Let's focus on triangulation techniques
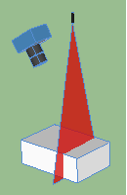
A linea laser illuminates a section of the object. Knowing the position of the camera and the laser is possible to obtain the coordinates of the various points illuminated by the laser. To scan the object it is necessary that the laser or the object moves. Image is obtained “dense”, that is, you have good data on all points of the surface.
This technique is even more than the other color independent; on the other hand you can not get them even if they were needed. It is used for a variety of applications, from robot guide to quality control.

Using two cameras, that taking an object from different angles allow stereoscopic vision framed by two points (similar to human vision). It ‘s just a single image (snap), you can then apply this technique on both stationary and moving objects.
The picture is not very dense, that means you do not have all the object points ( but from the points scored you will still have good data). If you want you can get the colors of the object
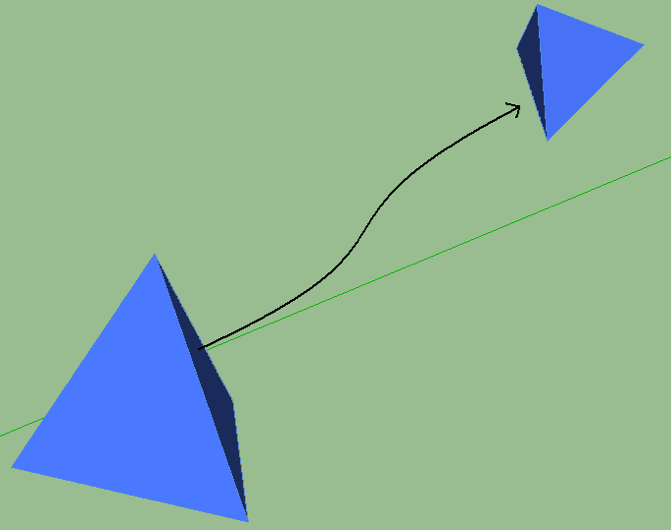
It requires that the object part you want to study is all on the same surface (a plane in space). Considering the size and the perspective deformation you can obtain the object position in the space. It works on a single image (snap). Generally it doesn’t require any special illuminators. You just need a camera.
It’s an exhaustive technique. You consider all the possible object rotations (at least on the corners of potential interest). They serve many edges easily visible.It works on a single image (snap). Generally it doesn’t require any special illuminators.
It requires a static object and make a dozen images from different angles. It ‘s slow but it has a precise technique. It can be used for measurement and reverse engineering, but not for the robot guide.
Several shots of a single object made by a camera. You can see the edges, eg. It is suitable for a cube but not for a sphere. It’s necessary a comparisons with a full CAD object model because it is not sufficient the comparison with some reference image.
It’s a slow method. It’s only a camera and generally does not require a special light source. It’s suitable for robot guidance applications for which low accuracy is sufficient.
| Triangulation technique | Conditions | Advantages | Disadvantages | Typical applications |
|---|---|---|---|---|
| Laser | Motion | Dense | No colors | All (robot guide, quality control) |
| Stereoscophy | Snap | Even colors | Sparse | Robot guide |
| Homography | Snap | Very fast, usually no illuminator | The whole area on one level, not accurate | Tracking objects |
| Pattern matching | Snap | Generally no illuminator | Exhaustive technique | Tracking objects |
| Fringe | Static | Precise, a single camera | Slow | Reverse engineering, measures |
| Multiple Views | Snap | Only one camera, no illuminator | Slow, need cad model and edges | Robot guide with low accuracy |